

Patient safety continues to be an issue in 2023, with nearly 1 in 4 patients experiencing an adverse event upon admission. Up to 40% of adverse events were related to medications given in the hospital, underscoring the importance of post-market drug surveillance and sufficient bedside staffing.
For the former, consumers and healthcare professionals are encouraged to report adverse events to the FDA. The information is captured in the FDA Adverse Events Reporting System, which is used to improve product safety and protect public health. In recent years, NLP has helped the FDA identify causal relationships between products and adverse events. A recent initiative is now evaluating LLMs to improve efficiency and accuracy.
From a technical lens, this was a topic I explored in my September talk on LLMs. I covered 2 healthcare demos for using LLMs with LangChain, and LLMs with SQL databases.
This tutorial will demonstrate using LLMs and LangChain to quickly summarize an adverse events report.
Prerequisites:
- Basic knowledge of OpenAI
Environment:
- Python: 3.11.6
- OS: MacOS 12.7.1
- VS Code: 1.84.1
All resources can be found here.
Generate an ADE report
Individual Case Reports for adverse events are typically requested through the FDA. A sample report is shown below:

For the purpose of this tutorial, I used OpenAI’s ChatGPT (GPT-3.5) to generate a synthetic adverse events report. I chose warfarin, as it is in the class of drugs that have resulted in serious adverse drug reactions.
These were the series of prompts I used to generate the final report:
“Create an adverse event report for warfarin that is submitted to the FDA”
“Fill out the report with hypothetical information”
“Remove the placeholders [ ]”
“Rewrite the event as a narrative, not a list”
A snippet of the report is below:
On November 10, 2023, Mr. John Doe, a 65-year-old male with a medical history of hypertension and atrial fibrillation, was brought to our attention at ABC Medical Center. The patient had been prescribed warfarin (5 mg daily) for his atrial fibrillation.
Q&A application overview
This LangChain blog post provides a high-level overview for building a Q&A application.
The main steps include:
- Load documents
- Split documents into chunks
- Create embedding vectors from chunks
- Store vectors in vector database
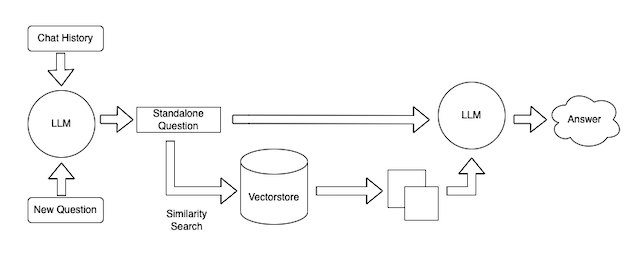
- Retrieve relevant documents from database
- Pass relevant documents to LLM
- LLM generates final answer
Ingest Data:
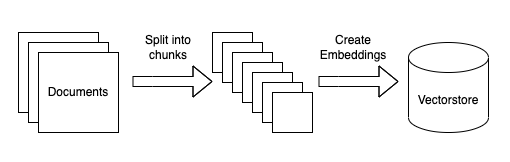
Query Data:
Set the OpenAI API Key
Navigate to OpenAI to obtain the API Key. This will be needed to authenticate requests to the API.
1
2
3
4
# set API keys to authenticate requests to the API
API_KEY = '<API Key>'
os.environ["OPENAI_API_KEY"] = API_KEY
Use LangChain to load documents into a vector store
LangChain is a framework for developing applications powered by LLMs. The main idea is that developers can “chain” different components around an LLM to create more powerful use cases.
Hence, we can connect LLMs to documents.
LangChain has many different methods to load documents. TextLoader is used to load in a text document and create a vector representation using the VectorStoreIndexCreator:
1
2
3
4
5
# load text document
loaders = TextLoader('<path to text document>')
# create a vector representation of the loaded document
index = VectorstoreIndexCreator().from_loaders([loaders])
The VectorStoreIndexCreator handles steps 2-4 above (chunking, embedding, and storage). This article goes into more detail about the class, including customization.
The default settings to note are:
- Chunking - uses RecursiveCharacterTextSplitter() to divide text at specific characters
- Embedding - uses OpenAIEmbeddings to generate embeddings
- Storage - embeddings are stored in Chroma, an open-source vector store
Set up Streamlit app
With Streamlit, we set up a simple web app to allow users to ask questions of the document:
1
2
3
# display the page title and the text box for the user to ask the question
st.title('🦜 LangChain: Chat with Adverse Events Report')
prompt = st.text_input("Enter your question")
Query the vector store
When a user passes in a question, the store is queried to retrieve the data that is ‘most similar’ to the embedded query.
1
2
3
4
5
6
# get response from LLM
if prompt:
response = index.query(
llm=ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0.2),
question = prompt,
chain_type = 'stuff')
Under the hood, we pass in the ChatOpenAI model (gpt-3.5-turbo) and set the temperature. The temperature controls the randomness of the output generated (closer to 1 will generate a more creative response). chain_type = ‘stuff’ combines the question and relevant document chunks into a single prompt to pass to the LLM.
This visual shows the overall workflow:
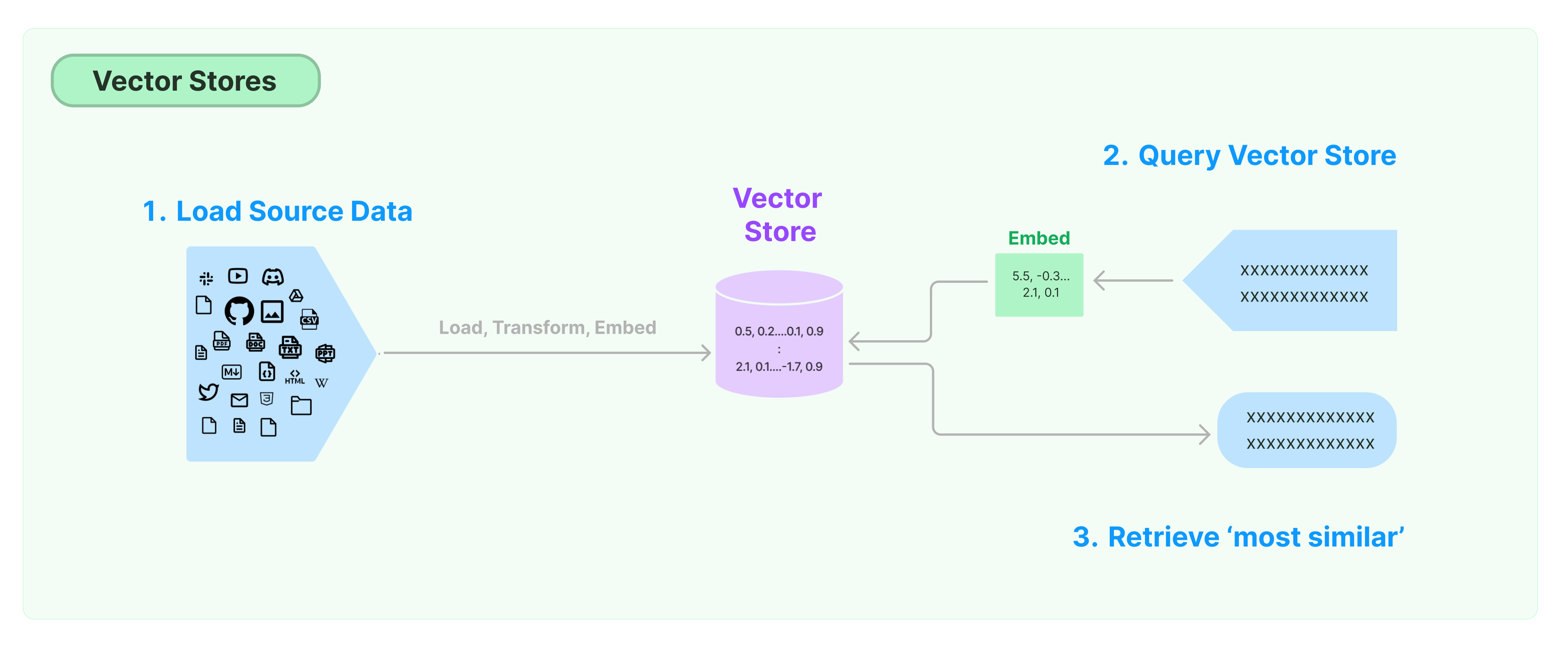
Let’s summarize
With Streamlit running, we prompt the document by asking a question followed by a summarization task:

Conclusion
In this tutorial, we explored using LLMs and LangChain to retrieve information from an adverse events report. LangChain is a framework for building LLM-based applications, such as a chatbot. Although NLP is not new, I was surprised by the ease of using natural language prompts to retrieve information. I think LLMs can make adverse events analysis more efficient, and improve product safety.
It would be interesting to test out LLMs on different types of documents (i.e., Standards of Care), and build out an advanced UI with Streamlit. I will explore these in a future post.
References
- https://www.nbcnews.com/health/health-news/nearly-1-4-us-hospital-patients-experience-harmful-event-study-finds-rcna65119
- https://www.fda.gov/drugs/surveillance/questions-and-answers-fdas-adverse-event-reporting-system-faers
- https://www.lifescienceleader.com/doc/how-the-fda-views-natural-language-processing-0001
- https://www.fda.gov/about-fda/nctr-research-focus-areas/bertox-initiative
- https://openai.com/
- https://www.ncbi.nlm.nih.gov/books/NBK519025/
- https://github.com/hwchase17/chat-your-data/blob/master/blogpost.md
- https://python.langchain.com/
- https://medium.com/@kbdhunga/enhancing-conversational-ai-the-power-of-langchains-question-answer-framework-4974e1cab3cf
- https://streamlit.io/